Hadoop下一代分布式文件系统HDFS联邦
|
biansutao
2011-11-18
HDFS 联邦 HDFS联邦,通过一个清晰的分离的命名空间和通用的数据块存储层, 改进了现有的HDFS架构。 HDFS联邦在集群中支持多个命名空间来提高可伸缩行和隔离。HDFS联邦扩大了HDFS集群对新的实现和使用案例的适用性。a 当前HDFS概况 HDFS有两个主要的层级划分,命名空间和数据块存储 命名空间
它管理着目录,文件和数据块。它支持文件系统的各种操作,例如:创建文件,修改文件,删除文件,列出
文件和目录。
数据块存储分为两部分
数据块管理
维护集群中的数据存储节点。它支持数据块相关的操作例如,创建,删除,修改数据库块,获得数据
块的位置。它也关注复制的位置和复制的因子(译者注:复制的块的数目)
物理存储
存储数据块和提供对数据块的读写访问。
当前的HDFS架构在整个集群中允许且仅允许一个单独的命名空间。命名空间被一个单独的namenode节点所管理。这种架构决策实现简单。可是,以上的架构分层实现在实际的实践中导致了一些限制。 仅仅在像Yahoo和Facebook这样的公司才会面对这样的限制问题。这些限制在HDFS联邦中被解决了。
命名空间和块存储的紧耦合 在namenode节点中,当前的命名空间和块存储的使用方式已经导致了这两个层的紧耦合。这使得实现多个namenode节点成为了一个挑战并且限制了其他服务直接使用块存储。
命名空间的伸缩性 HDFS集群的存储可以通过添加datanode节点实现水平伸缩。命名空间就不能实现水平伸缩。 当前的命名空间仅仅能通过在一个单独的namenode节点上实现垂直伸缩。namenode在内存中存储着整个文件系统的元数据。这限制了文件系统支持的数据块,文件,目录的数量。 这些数据在单独的namenode的内存中容量是有限的。 在Yahoo一个典型的集群部署,包含2700-4200个datanode节点,包含着1.8亿文件和数据块,总共有25PB的数据。 在Facebook HDFS有大概2600个节点3亿个文件和数据块,占用着60PB的存储空间。Hadoop系统对于大多数Hadoop用户来说足够好了,只有少数的超大型应用需要解决命名空间缺乏伸缩性的问题。 性能 单独的namenode节点限制了文件系统的吞吐,当前支持6万个并发任务的管理。下一代的MapReduce将支持超过10万个并发任务,要达到这个目标需要有多个namenode节点。
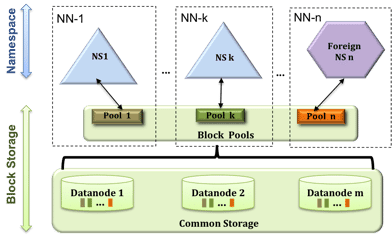
隔离 在Yahoo和其他需要公司,集群同时分别被多个用户使用。单独的namenode节点在这种环境之下无法实现隔离。一个分离的命名空间提供给一个用户使用是不可能实现的。一个过载的试验性应用可能导致其他产品的应用速度减慢。一个单独的namenode几点也不允许隔离不同的应用(例如:Hbase)的目录到一个分离的namenode空间中。 HDFS联邦 I 为了实现水平伸缩命名服务的目的,联邦使用了多个独立的namenode节点/命名空间。namenode节点被联邦制,命名节点是独立的并且不用和其他命名节点保持数据的一致性。datanode节点被当作通用的块存储节点被所有的namenode节点使用。每一个datanode节点注册在集群中的所有namenode节点中。datanode节点周期性的发送心跳,块报告和处理命令到namenode节点。 块池是一个归属于一个单独的命名空间的块的集合。datanode节点在集群中,为所有的块池存储数据块。 块池之间保持独立,互不干扰。这允许命名空间为新的块生成块ID而不需要和其他的命名空间保持一致性。 一个Block Pool的失败并不妨碍为集群中的其他的Block Pool 和datanode节点。. 一个命名空间Block Pool在一起被叫做命名空间卷. 它是一种自包含的管理单元。 当一个namenode/namespace被删除的时候,在datanode节点中的对应的Block Pool 也会被删除。 集群进行更新的时候,每一个命名空间卷作为一个单元被更新。 伸缩性和隔离性 支持文件系统命名空间的多namenode节点的水平伸缩。为用户和应用程序目录分离命名空间卷且改进了隔离性。 通用存储服务 Block Pool 抽象开辟了未来的创新架构。 新的文件系统可以建立在块存储之上。新的应用可以直接的建立在块存储层上而不需要使用文件系统接口。新的块池分类也成为了可能,区别于默认的块池。例如,包含一个块池的MapReduce tmp 文件存储使用不同的垃圾回收机制,块池缓存的数据比分布式的缓存更有效。 设计简单 我们考虑了分布式namenode节点方式并选择了联邦的实现方式,是因为他的简单和易于实现。 namenodes和namespaces 是彼此独立的,对于现存的namenodes只需要很少的改动。namenode节点的鲁棒性不会受到影响。联邦也保留了对配置的向后兼容。现存的Namenode的部署不需要任何的配置更改。 实现这些特性和保持新版本的稳定一共花费了4个月的时间。namenode只有很少的改动,大部分的改动在datanode节点上。在存储上引入了块池作为一个新的层次结构,Map的副本和其他的内部数据结构的改动。 其他的改动还有对现有的新的程序的数据结构改动的测试,创建一些工具对联邦集群的简化管理。 结论及致谢 HDFS Federation was developed in HDFS-1052 branch. Please see HDFS-1052, the umbrella JIRA for the detailed design and the sub tasks that introduced the federation feature. The feature has been merged into trunk and will be available in 0.23 release. The design of this feature was driven by Sanjay Radia and Suresh Srinivas. The core of the implementation was done by Boris Shkolnik, Jitendra Pandey, Matt Foley, Tsz Wo (Nicholas) Sze, Suresh Srinivas and Tanping Wang. The client-side mount table feature was implemented by Sanjay Radia. The feature development was completed while the team was at Yahoo!. We are continuing to test and enhance this feature further at Hortonworks. Stay tuned for an upcoming blog by Sanjay Radia on the client-side mount table, which will discuss how to manage multiple namespaces in the federated HDFS cluster. – Suresh Srinivas
|

{kind=link}
{kind=link}
相关讨论
相关资源推荐
- Jeecg Boot 2.2.1 版本发布,基于SpringBoot的低代码平台
- jeecg-framework-3.3.2-RELEASE 最新版本发布
- linux基础进阶笔记
- IMG20241115211541.jpg
- Sen2_ARI_median.txt
- 毕业设计&课设_基于 flask-whoosh-jieba 的代码,涉及文件管理及问题修复.zip
- 基于springboot家政预约平台源码数据库文档.zip
- Ucharts添加stack和折线图line的混合图
- 基于springboot员工在线餐饮管理系统源码数据库文档.zip
- 2015-2021年新能源汽车分地区、分类型、分级别销量逐月数据和进出口数据-最新出炉.zip